import pandas as pd
df = pd.read_csv("../../data_sources/coffee_survey.csv")
import matplotlib.pyplot as plt
import seaborn as sns
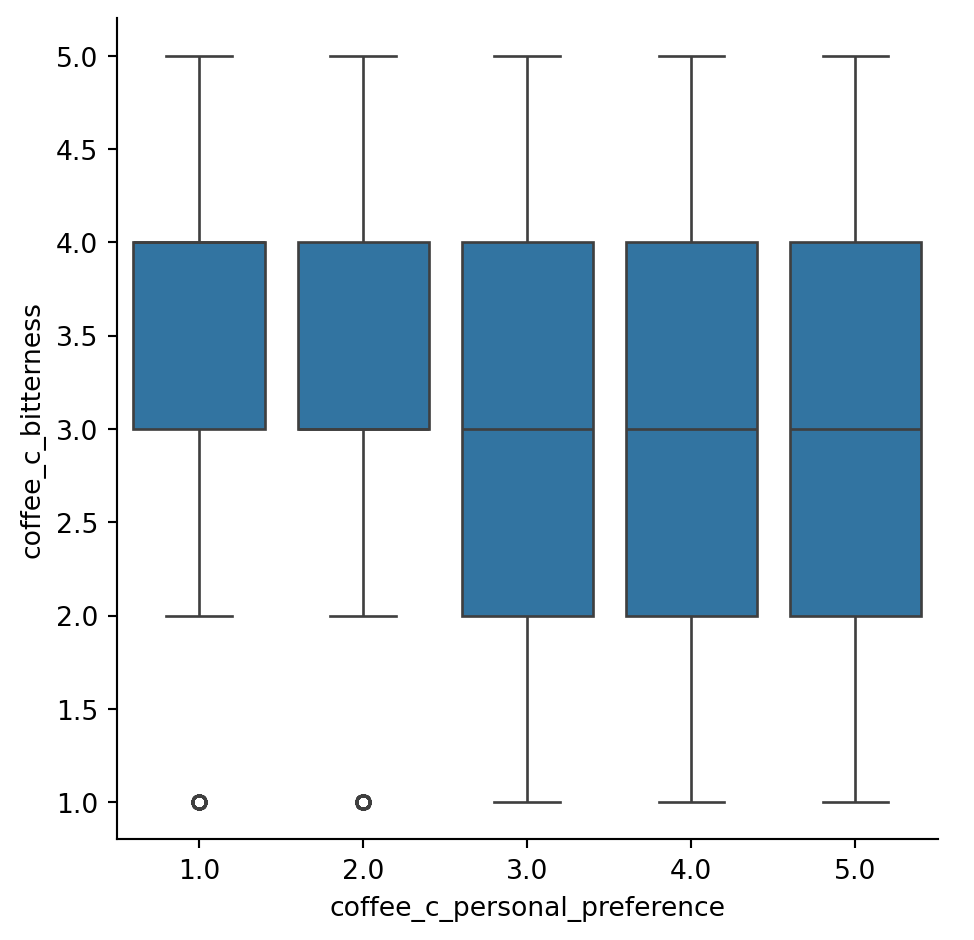
sns.catplot (data = df,
x = "coffee_c_personal_preference",
y = "coffee_c_bitterness",
kind = "box")