Set up code
#Import data
import pandas as pd
df = pd.read_csv("../../data_sources/gapminder.csv")We will first load the essential packages and dataset
#Import data
import pandas as pd
df = pd.read_csv("../../data_sources/gapminder.csv")df.columns
df.info()
df.describe()
df.dtypes
df["lifeExp"]
df["lifeExp"].unique()
df["lifeExp"].describe()
df["continent"].describe()
df["continent"]<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 1704 non-null object
1 year 1704 non-null int64
2 pop 1704 non-null float64
3 continent 1704 non-null object
4 lifeExp 1704 non-null float64
5 gdpPercap 1704 non-null float64
dtypes: float64(3), int64(1), object(2)
memory usage: 80.0+ KB0 Asia
1 Asia
2 Asia
3 Asia
4 Asia
...
1699 Africa
1700 Africa
1701 Africa
1702 Africa
1703 Africa
Name: continent, Length: 1704, dtype: objectsubset_con=df[["continent", "gdpPercap", "year"]]
summary_con= subset_con.groupby("continent")["gdpPercap"].mean()
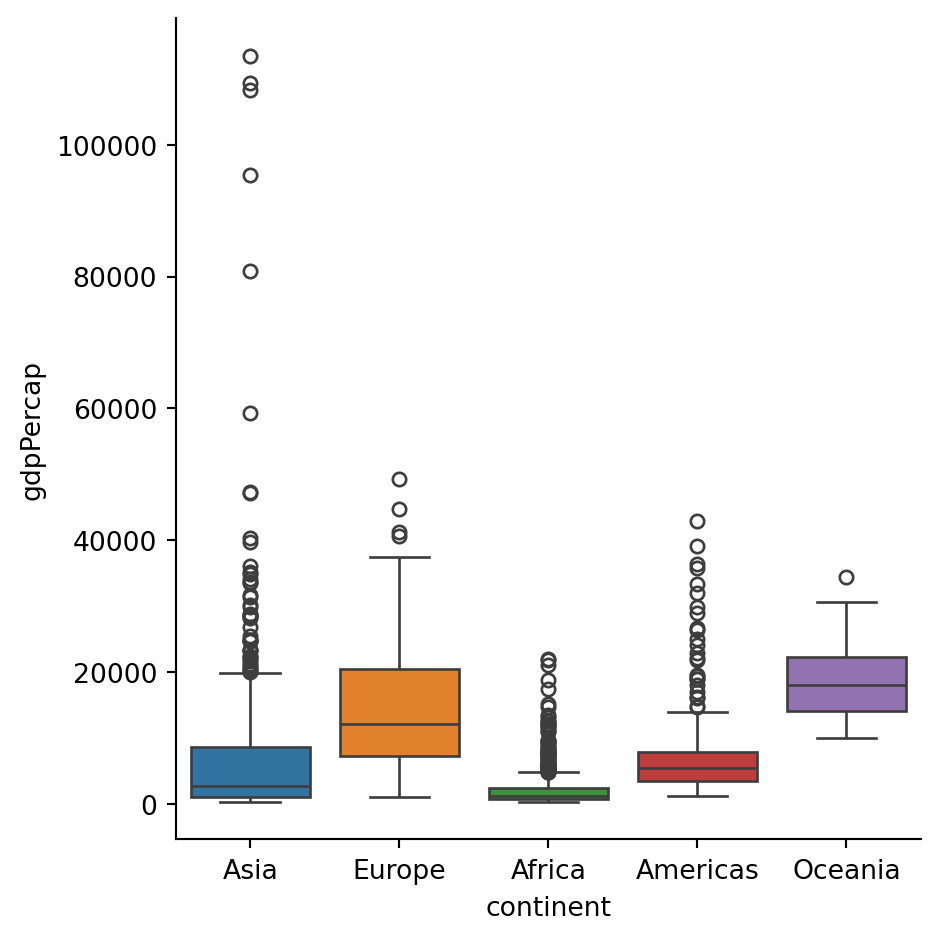
summary_con= summary_con.reset_index()Summary of mean GDP per Cap in different continents
import seaborn as sns
sns.catplot(data=df,
x="continent",
y="gdpPercap",
kind="box",
estimator="std",
hue="continent"
) 
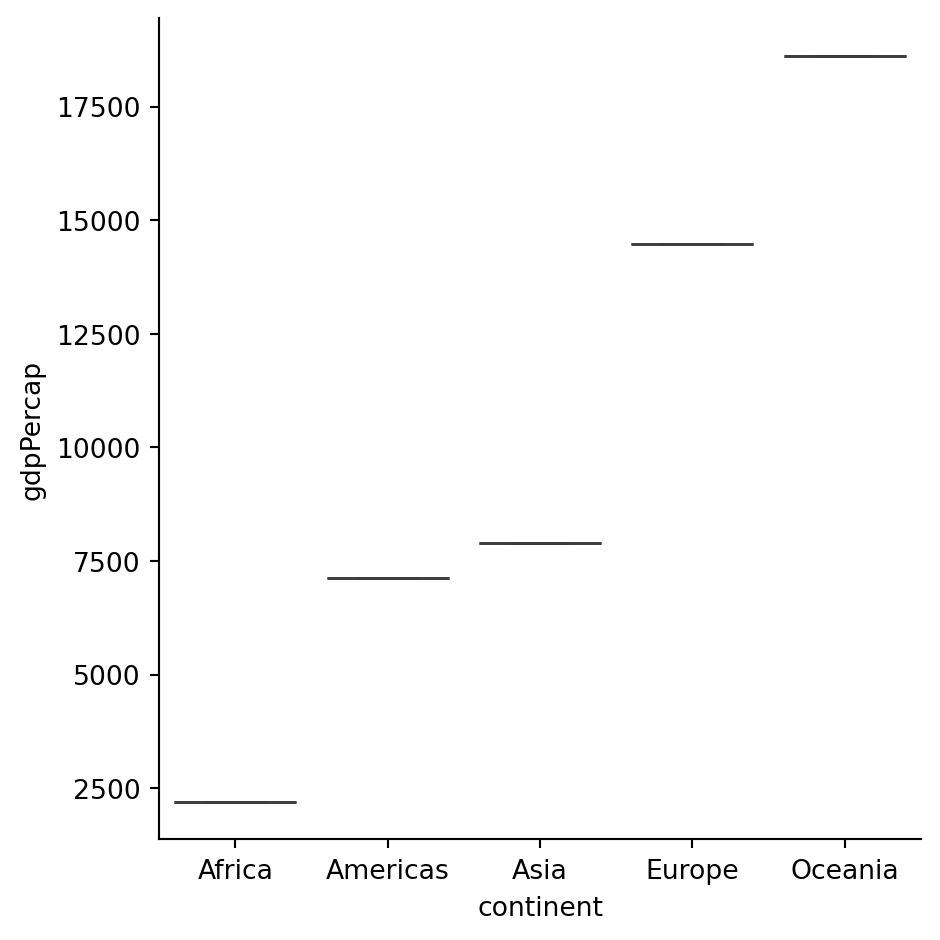
Summary of GDP per Cap in different continents
sns.catplot(data=summary_con,
x="continent",
y="gdpPercap",
kind="box",
estimator="std",
hue="continent"
) 
import plotly.express as px
import matplotlib.pyplot as plt
px.scatter(data_frame = df, x = "continent", y = "gdpPercap", color = "continent")We will now visualize it on a world map
# Compute mean GDP per capita per continent
continent_gdp = df.groupby("continent")["gdpPercap"].mean()
# Map each country's continent GDP
df["continent_gdp"] = df["continent"].map(continent_gdp)
# Drop duplicates to keep only one row per country
country_continent_gdp = df.drop_duplicates("country")[["country", "continent_gdp"]]
#plot
px.choropleth(country_continent_gdp,
locations="country",
locationmode="country names",
color="continent_gdp",
color_continuous_scale="Plasma",
title="Continent-Level Avg GDP per Capita (Mapped by Country)",
labels={"continent_gdp": "Continent Avg GDP"})GPD per Capital in different continents